Detection and Segmentation¶
1 Slow R-CNN Training¶
在训练结束时,要给每一个region proposal 打上一个positive, negative或者neutral打标签,接着和ground truth boxes进行比较
训练时会忽略掉neutral 的region proposal
接着将所有region proposals 会被裁剪成固定的大小,传入独立的卷积神经网络,共享权重,预测类别和边界框,
2 Faster R-CNN¶
Anchor -> Region proposal -> Object Box
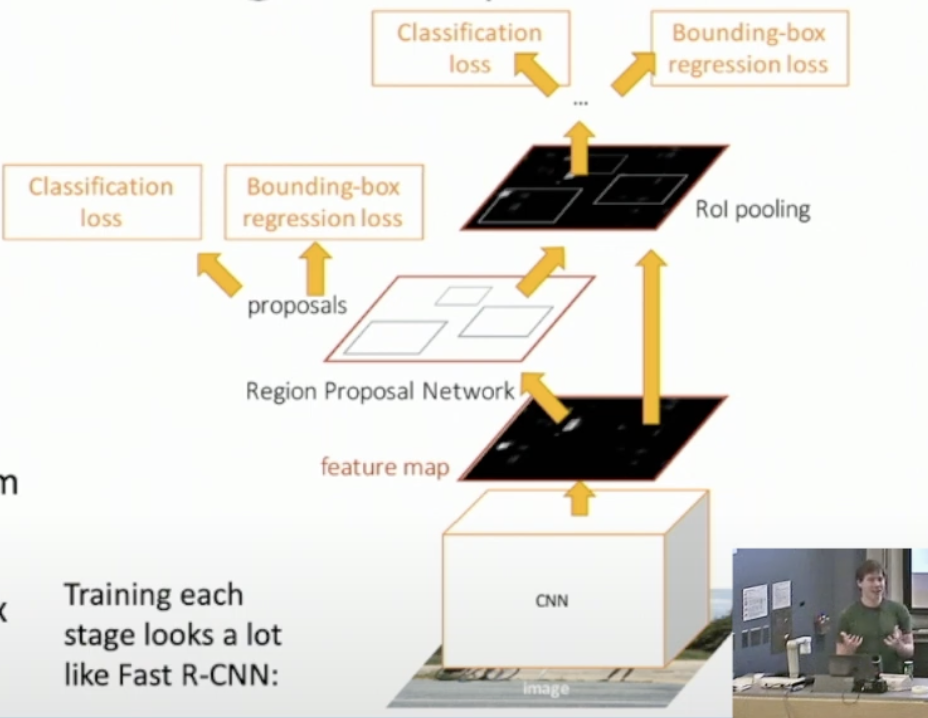
3 Object Detection Methods¶

4 CornerNet¶
无需Anchors进行检测
主要思想是改变边界框的参数化方式, 只用左上角和右下角来表示边界框
对于我们要预测的每类对象, 我们会预测出一个 "左上角概率热图" 和 "右下角概率热图", 对于每个像素还预测一个嵌入向量来决定哪些左上角和右下角匹配

5 Semantic Segmentation 语义分割¶
给图片中的每一个像素点一个类别标签

不用区分统一类别的不同实例
5.1 Sliding Window¶
在像素点周围提取一个小照片,进行分类
5.2 Fully Convolutional Network¶

全连接卷积网络只有卷积层, 最终输出是通道数为分类数的三维张量
事先确定组别的数量
为了做出更好的决策, 我们希望决策依赖于输入图像中一块较大的区域, 如果用 3 3 的卷积核需要很多层才能积累到较大的感受野, 这样的计算可能在高精度图像上非常昂贵
于是我们需要通过下采样(downsampling) 和上采样(upsampling)* 来加速过程
- Downsampling: 池化,有一定步长的卷积
- Upsampling:
- Unpooling:
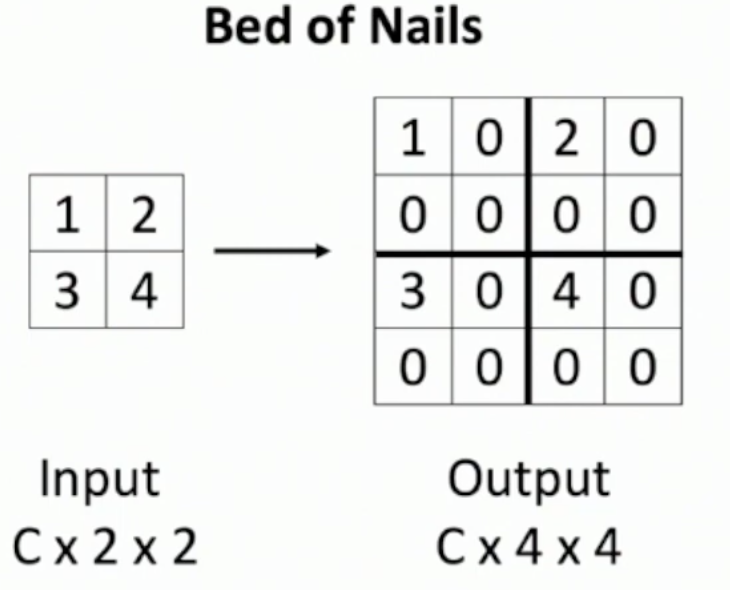
- Nearest Neighbor: 用同样的数字填充
- Bilinear Interpolation:

- Max Unpooling: 记住MaxPooling 中,记住每个选取出的数字的位置,在Unpooing的过程中填回原来的位置
- Unpooling:
将每个下采样层和上采样层一一配对,选择哪种上采样取决于对应下采样的方式
Transposed Convolution: 可学习的上采样
步长大于 1 的卷积可以理解为一种可学习的下采样, 我们如果使得步长小于 1, 岂不是就在做可学习的上采样, 输出大于输入了?

我们用输入张量的元素乘以卷积核得到 3 3 的输出, 将输出加到输出张量上, 对重叠部分求和*, 然后移动一格输入, 移动两格输出, 继续反卷积下去
6 Instance Segmentation¶
在计算机视觉和语义分割中, 有 "stuff" 和 "thing" 的概念
"stuff" 是不可数的, 通常为背景的物体, 例如草地, 天空, 没有明确的形状大小
"thing" 是可数的, 独立存在的物体, 例如人, 车, 有明确形状和大小, 可以被区别为不同的实例
语义分割任务更进一步就到了实例分割(instance segmentation), 要求把所有 "thing" 的实例都分割出来, 例如牛群中的每头牛, 这个任务基于目标检测算法, 对于每个检测出的对象, 要输出一个分割掩码(segmentation mask)
6.1 Mask R-CNN¶
建立在 Faster R-CNN 的基础上, 增加一个头,对每个检测出的对象上再跑一个 FCN 结构


7 Panoptic Segmentation¶
为所有的像素打上标签,同时区分不同的things
这些分割算法可以应用在人体位姿估计, 在人体各处设置多个关键点, 在 Mask R-CNN 上再加一个头(Head)来预测关键点就行