Attention¶
Seq2seq with RNNs: Encoder + Decoder
Encoder: n to 1 Decoder: 1 to n

一旦我们处理了输入向量,我们希望以某种方式总结整个向量一个是decoder网络的初始隐藏状态\(s_0\),还有一个上下文向量\(c\)
在这种情况下, 输入序列的长度成为瓶颈,所以需要一个机制,不将所有信息转化为一个长向量c
1 Attention 机制¶
使用allignment function,参数化为一个全连接神经网络,输入向量分别是initial decoder vector 和 当前隐藏状态,会输出一个分数,表示对编码器每个隐藏状态的关注程度
接着使用softmax将分数转化为概率分布,即注意力权重
然后对每个隐藏状态进行加权求和,形成上下文向量\(c_1\)
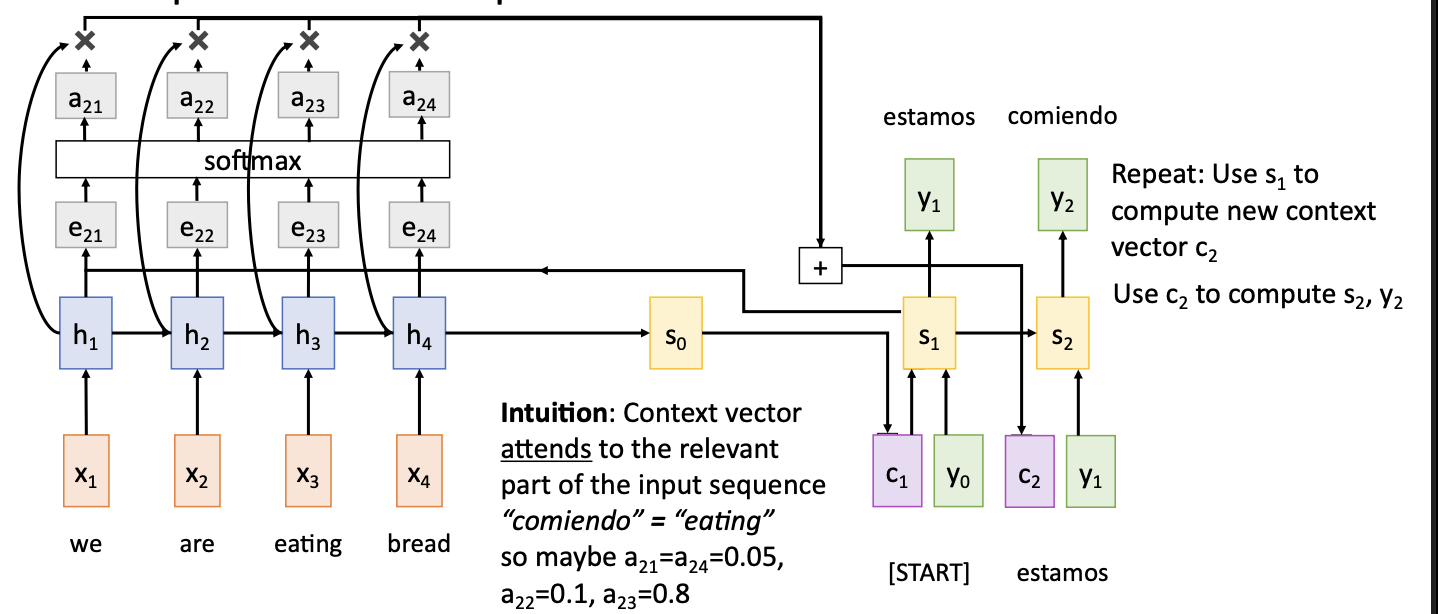
下一步,将\(s_1\)与各个hidden state进行比较,softmax之后输出新的上下文向量\(c_2\),用于计算\(c_2\),以此类推
通过在decoder的每个时间步骤使用不同的context vector, 输入序列不再被单个向量瓶颈,每个时间步骤时, 上下文向量重视输入序列的不同的部分
注意力机制实际上并没有用输入是一个序列的事实,所以可以应用于其他类型的数据
2 Attention Layer¶
抽象化
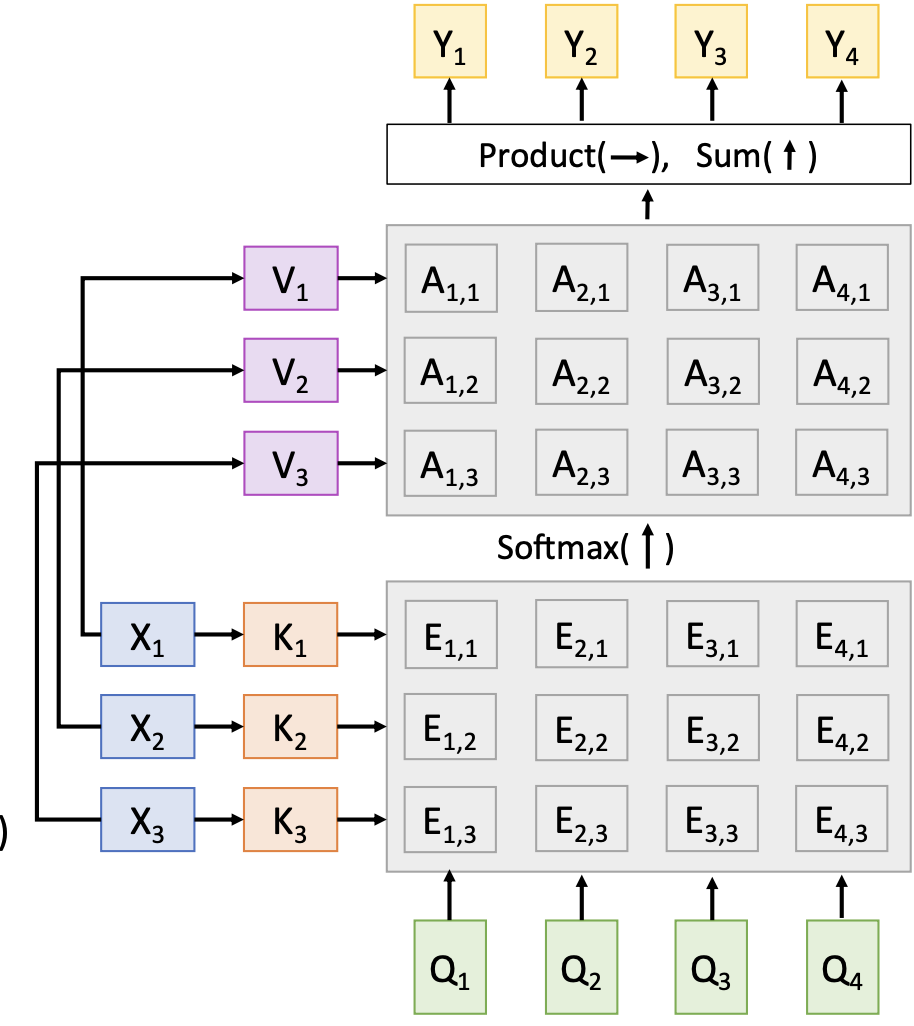
Inputs: - 查询向量:q(形状:\(D_Q\)) - 输入向量:X(\(N_x\times D_x\)) - Similarity function: \(f_{att}\)
Computation: - Similarities:\(e = f_{att}(q,X_i)\), (Shape:\(N_x\)) - Attention weights: \(a = sofrmax(e)\), (Shape: \(N_x\)) - Output vector: \(y = \sum_i a_i X_i\)

在仅仅使用向量点积作为similarity function 的时候,如果有一个值非常大的话,那么其他值在经过softmax之后都会非常接近0,会引发梯度消失问题
所以在计算相似性时我们使用缩放点积来防止梯度消失
在只有一个查询向量的时候,每个时间步我们有一个query,用这个query在所有的输入向量上生成一个概率分布
有一组query vector的时候,每个query vector 在每个输入向量上生成一个概率分布,接着再次使用输入向量来产生正确的输出
实际上input vectors在注意力层中有两种用途,一个是使用输入向量来计算注意力权重
将Input vector分解为一个Key vector和一个Value vector,使用两个可学习的权重矩阵Key matrix和Value Matrix将Input vectors分解为K,V,用K来计算相似度,用V来结算输出
3 Self-Attention layer¶
只有一组Input vector 作为输入,要做的是将Input vector中的一个向量与另外一个向量进行比较
Query vector由自己生成

如果我们改变输入的顺序, 可以注意到输出的顺序也会同步改变, 这说明自注意力层是有置换同变性(permutation equivariance)(PE)的, 它不关心输入的顺序, 如果我们想要关心顺序的话, 我们要给每个 引入位置编码 (positional encoding)
4 Masked Self-Attention Layer¶
有时我们希望防止模型知道未来的时间步的信息, 所以要相应更改权重掩码(mask)

比如在图片中,在由\(Q_1\)生成时希望他不能用到后面时间步的信息,所有设置为负无穷大,这样softmax之后会给他0的权重
5 Multihead Self-Attention Layer¶
我们将输入向量分割成多个部分, 并在多个并行的自注意力层上独立的处理这些部分, 从而增加模型的表示能力

需要用到的超参数: - \(D_Q\): query dimension - \(H\): Number of heads
6 Transformer¶
Three ways of Processing Sequences
- 递归神经网络,擅长处理长序列,但是无法并行
- 1D-Convolution, 高度并行,但是不擅长处理长序列
- Self-Attention, 集上两种方法的优点,但是会占用大量的内存
如何将三种方法组合起来呢?Transformer
将Self-Attention作为比较输入向量的唯一机制,接受input sequence, 经过 Self-Attention 块之后,每个输出都是由每个输入决定的。
接着进行 Residual connection, 然后进行 Layer Normalization
这里用层归一化(layer normalization)而不是 batch normalization 是因为:
- 它不依赖于批次大小, 这在处理可变大小的输入或在推理时使用不同的批次大小时非常有用。相比之下, 批量归一化可能在小批次或不一致的批次大小下不稳定性
- 层归一化适应顺序数据, 而 transformer 模型通常用于处理顺序数据(如文本或时间序列)
- 层归一化更容易与自注意力机制结合使用, 由于自注意力机制处理的是序列中的每个元素, 层归一化的逐元素归一化策略与之更加兼容

自注意力层是向量之间交互的唯一的地方,层归一化和mlp对每个vector独立进行
A Transformer is a sequence of transformer blocks
Transfer Learning - Pretraining: 从互联网下载大量语料,训练一个基于transformer的大语言模型 - Finetuning: 根据自己的NLP task微调Transformer
7 Vision Transformer¶
介绍:https://zhuanlan.zhihu.com/p/445122996
当拥有足够多的数据进行预训练的时候, ViT 的表现会超过CNN, 可以在下游任务中获得较好的迁移效果
但是当训练数据集不够大的时候, ViT 的表现通常比同等大小的 ResNet要差一些