Training Neural Networks¶
1 Learning Rate¶
从高学习率开始逐步降低
1.1 learning rate decay¶
step: 从一个learning rate开始,经过一定的epoch降低学习率,固定的点
增加了新的超参数:在哪些点衰减
Cosine: 余弦学习率衰减 \(\(\alpha_t = \frac 12 \alpha_0(1+\cos(\frac{t\pi}{T}))\)\)
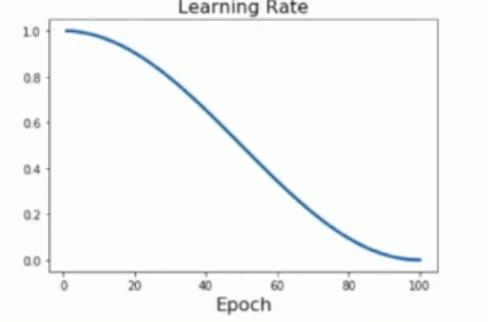
训练时没有引入任何新的超参数,因此更容易调整
Linear:\(\(\alpha_t = \alpha_0(1-t/T)\)\)
Inverse Sqrt:\(\(\alpha_t = \alpha_0/\sqrt t\)\) 一开始下降很快,但在后面变化很慢
2 How long to train?¶
Early Stopping: 训练了很长时间或者模型在验证集上的表现变差的时候停止训练,在训练过程中即使报错不同时间点的模型快照
3 Choosing Hyperparameters¶
3.1 Grid search¶
为每一个超参数选择若干个备选值,对所有的可能情况进行评估
3.2 Random Search¶
指定超参数的范围,对超参数取随机值,进行多次的尝试
3.3 Random vs Grid Search¶
网格搜索可能不知道参数相对于性能的分布,那么选取值时不能找到最优的超参数
随机搜索对于影响更大的参数能够尝试更多的值
3.4 Without tons of GPUs¶
- Check initial loss without weight decay
- 尝试对非常小的样本过拟合:trun off regularization
- loss 几乎不变:学习率太低
- loss 爆炸:学习率太高
- 找到使loss快速下降的学习率
- 粗略的超参数网格,训练1-5epoches
- 从第4步中得到的模型中挑选好的,重新优化网格,训练更长时间,without weight decay
- 查看学习曲线
- 返回第5步
若训练集和验证集的准确率差不多,很可能是欠拟合,需要 训练更长时间,用更大的模型,减少正则化
需要调整的参数: - 网络结构 - 学习率,学习率衰减策略,学习率更新方式 - 正则化方式
4 After training¶
- Model Ensambles
4.1 Transfer Learning¶
Transfer Learning with CNNs
1. 在一个大数据集上(例如 ImageNet)训练模型
2. 删除最后一层(分类层), 冻结剩下层的权重, 相当于用 CNN 提取了图像特征
3. 加入我们需要的分类层, 在任务的数据集上训练(可选)
如果我们拥有较大的数据集, 我们可以在原来网络的基础上进行微调训练, 可以冻结层数较低的层以节省训练资源, 建议以原始学习率的 1/10 进行训练
如果数据集较小(无法微调), 并且与 ImageNet 差距很大的话, 迁移学习效果就不好了
4.2 Model Parallelism¶
- Idea1: Run different layers on different GPUs, 但是GPU会花很多时间等待
- Idea2: 在不同的GPU上运行模型不同的分支,同步是一个问题,需要通信梯度等等
Data Parallelism: Copy Model on each GPU, split data

如果你有很多 GPU, 可以通过并行 GPU 来提高采样的数量(Large-Batch Training), 这样可以加速训练, 但注意批归一化只能在 GPU 内部进行
在具体实现上, 如果有 \(k\) 个 GPU, 我们将 batch size 改为 \(kN\) 并把 learning rate 改为 \(k\alpha\), 为了防止学习率过高, 我们让其从 0 开始在前 5000 个迭代中慢慢增长